Workshops
Amanda Hickman
Start here
If you haven’t already created accounts on both Workbench and Datawrapper please go ahead and do that.
This week we’re going to cover finding data, cleaning it up, and presenting it in chart form. When I come back on April 4, we’ll tackle mapping.
I’m assuming everyone has worked through either Paul Grabowicz’s Spreadsheet Tutorial or the Berkeley AMI interactive tutorial – the latter only works on Safari, but Paul’s walk-through works anywhere.
Charts in the Wild
Karen Hao and Jonathan Stray have done some reporting for The Algorithm looking at artificial intelligence in the justice system. Their story
Can you make AI fairer than a judge? Play our courtroom algorithm game is a great read, but I also really love Karen’s guided tour of the path they took from napkin sketches to final graphics.
Source publishes a lot of great “How we built it” stories that ought to inspire you. Their Q & A with Alvin Chang on his quick-turnaround Vox graphic that showed unanswered questions from the Kavanaugh hearings is great.
Meatless Burgers Stoke Sales and Questions About Nutrition in Wall Street Journal includes some nice clear charts.
Seattle Times reported on double booked surgeons – the charts they included provide another view of the story and illustrate what it actually means to double book a surgeon.
The IRE Awards are always an opportunity to get inspired by great data projects.
Oregon Live and The Oregonian ran a lengthy series on elder abuse including some charts that shed light on the kinds of abuses experienced in residential facilities. They also published a complete database of facility complaints.
Asbury Park Press analyzed quite a bit of data for their award winning reporting on renter hell. They didn’t produce a lot of charts but the numbers were still key to understanding where the story was.
Data visualization doesn’t have to be data driven. This chart of QZ Brexit paths helps tell a chutes-and-ladders like story.
Often charts are relatively simple. CalMatters ran a long report on families struggling to get mental health care and included a couple of charts that could use stronger captions but make fantastic pullquotes.
Star Tribune charts in their reporting on senior homes illustrate the scope of the problem.
The Intercept dug into data on terrorism prosecutions in the US. They also looked at sexual abuse of prisoners in ICE custody. Both took substantial digging.
Alvin Chang’s data viz explainer on how the rich got rich and the poor got poor in Vox is a great example of the ways that we can use data visualization to make sense of complex numbers. He also used potatoes to explain how a 70% tax rate would work and how tax brackets really work.
Amazon scraps secret AI recruiting tool that showed bias against women Reuters, October 9, 2018 has a nice clean chart of the sort that’s in our wheelhouse.
Homelessness in the Bay Area Spur: The Urbanist, October 23, 2017
Californians: Here’s why your housing costs are so high CALMatters, August 21, 2017
Why is Sacramento failing its black students? Sacramento News and Review, June 14, 2018
Data isn’t magic

What is the fastest way to reduce the number of murders in a single precinct?
Data is only as good as the people who enter it. Before you rely on data for your reporting you need to know who generated it and how the data you’re looking at got into the database.
Data is almost always entered by people. The fastest way to reduce the number of felony robberies in a single police precinct is to start classifying incidents as misdemeanors, and there’s good evidence that New York Police Department precincts did exactly that when the commissioner started rewarding precincts that got their serious crime rates down.
It isn’t clear why Baltimore County Police Department has more “unfounded” rape complaints than most departments nationwide, but BuzzFeed News found that many of those “unfounded” complaints were never really investigated. Sometimes there are just quirks in the way data gets recorded – one report found that coroners don’t have solid standards about how to decide whether to record a gun death as accident or homicide and as a result, accidental homicides are split between the two categories, making it hard to track down reliable data.
Data is powerful but it is never a substitute for picking up the phone and making some calls. If you’re just starting to think about where data fits in your reporting process, Samantha Sunne wrote an excellent introduction to the challenges and possible pitfalls of data journalism, and how you can you avoid them.
Finding and cleaning data
Data is a powerful reporting tool. It lets us scrutinize public spending and policy outcomes, challenge conventional wisdom and participate more fully in public conversations. A decade of open data activism has left reporters and the general public with unprecedented access to public payrolls, traffic reports, police data and much more. All of it allows us to hold policy makers accountable and understand the world in ways we couldn’t without access to the numbers.
Finding it
Whether you’re a seasoned data journalist or brand new to thinking about data as a source in your reporting, there are exceptional places to find data that you may never have considered. My most recent post on Source, The Totally Incomplete Guide to Finding and Publishing Data is an excellent resource.
Who has data now, and how can you get your hands on it?
The best way to start looking for data you need is almost always to ask yourself who could collect this data and look at where they might share it. Are there city, county, state, or national agencies that collect data? Do they publish it? If they don’t publish data, what happens when you ask for it? Sometimes all you have to do is ask, sometimes you have to file a more formal freedom of information request for the data.
Are there private research organizations or non-profits that keep data on the subject you’re researching?
Once you’ve exhausted the direct approach, or you’re just interested in sparking some inspiration, there are a few more great places to look for data and ideas.Lots of newsrooms push cleaned data (and code) to github but there’s not a unified way to find it all. Washington Post has released a collection of data on school shootings, police involved shootings, and unsolved homicides, along with valuable context about how the data was collected and processed. BuzzFeed News maintains an indexed overview of all the data they’ve published to github, as does 538. Here are a few more:
- Asbury Park Press (Asbury Park, NJ)
- Arizona Central recently launched a data hub.
- BuzzFeed News
- Courier Journal (Louisville, KY)
- Houston Chronicle (Houston, TX)
- Naples Daily News (Naples, FL)
- New Jersey Advance publishes their data on data.world
- New York Times maintains a repository that’s mostly code. They also publish some data via The Upshot
- News Press (Cape Coral, FL)
- NPR Visuals publishes mostly code.
- ProPublica (their GitHub repository includes more data as well as a fair amount of reusable code)
- Quartz includes data along with a ton of helpful code in their GitHub repository.
- Tallahassee Democrat (Tallahassee, FL)
- Vancouver Sun
- Washington Post
- 538
Chicago Data Collaborative includes data that newsrooms, academics and advocates have compiled to better understand criminal justice in Chicago.
Wireservice’s Lookup repository is a collection of very useful lookup tables for BLS, IPUMS and some Fed data. (Wireservice is a collaboration between a number of US newsroom developers and data reporters.)
More tips on searching for data and suggestions about where to find it are on my Workshop Wiki. Peter Aldhous has some fantastic tips for getting creative in his lesson plan from his Data Visualization course. Mago Torres has a few great stories about the benefit of a little creativity if you’re working on an international story. If the US won’t give you details of a meeting between US and Mexican officials, don’t assume you can’t get what you need from the Mexican government.
» Question: Is there data you are interested in finding and making sense of for your portfolio project? https://etherpad.opennews.org/p/maps_and_charts
Cleaning data
Once you have data, you’ll often find you have to do a bit of work to get it to a place where you can actually use it. Peter Aldhous has a great walk through that will show you how to use OpenRefine to clean up data. We’re going to use Workbench, only because I think it does a nice job of providing an easy to read audit trail. Workbench recently launched a mini intro to data journalism that is a great way to go deeper with Workbench.
We’re going to start with a CSV from the U.S. Energy Information Administration on regional oil production. The numbers given are thousands of barrels per day. (Specifically, I used their data browser to get “Total Petroleum and Other Liquids” from 2000 to 2017)
You can see my finished work on Workbench: https://app.workbenchdata.com/workflows/5908/ but don’t use “duplicate” – we’re going to walk through this from scratch.
- Start with an empty workflow. You might be asked to start by Choosing a Data Source. We’re going to “Add from URL”
-
Import the CSV – you can also download it and then upload it to Workbench, but we’re going to give Workbench a URL for the data we want to work with: http://amandabee.github.io/workshops/2019/advanced_media_institute/world_oil_production.csv
- Transform it into a functional table. One of the things I like about Workbench is that it logs every step so you can always see what you’ve done.
- “Delete Rows” to delete rows 1-3 and 5-8
- Delete that extra column
- Edit the cell that is missing a header
- “Rows to Header” to move the header where we want them
- Rename the columns to drop those annoying decimals:
region, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017This is one of the more exasperating features of Workbench. It is not great at working with years.
- Once we’ve got the data a bit organized, we can actually reshape it into something we might be able to chart.
- Select “Reshape” and then “Transpose” to transpose the data
- Use “Rename” to label the “year” column
- “Convert to Date and Time”
- “Line Chart”
Workbench’s charting is great for a quick glance but you’ll want to move over to another tool to do your actual visualization.
- In our last class someone pointed out that a few of these categories are kind of arbitrary. Eurasia encompasses the former Soviet Union. It seems non-crazy to combine that with Europe, or rename it.
- Use the ➕ to add a second tab.
- Our “source” for this tab is going to be “Start from tab”
- We can use our “Tab 1” data and look at the Calculate function to create a new column with the sum of Europe and Eurasia.
Chart It
You have to make your Workbench Workflow “Public” (top right of the screen ↖️) but once you do, you can take the “live” URL for your CSV over to Datawrapper and make a much nicer chart.
- Pick the “Step” you want to chart. Probably the last step before the chart.
- Every step produces a unique URL, which is incredibly handy but also definitely a recipe for confusion.
- If your CSV isn’t clearing Datawrapper’s checks, make sure that you published it!
Publishing your data makes the whole workflow accessible. There are cases when you will want to mask some of your tracks and migrate just the final data to a new workflow.
But if you really, really need to cover your tracks, you should read Workbench’s terms of service. I’ve never had a conversation with them about how they expect to respond to subpoenas, for instance.
More Data Cleaning
We won’t walk through these in class, but below are a few more walk throughs that will help you get the most out of Workbench’s data cleaning capacities.
USA Spending tracks federal government spending. We can use their Advanced Search to pull up a list of grants to DUNS 9214214 and 124726725, aka Berkeley and Stanford. The data they provide is a lot cleaner than it was in 2014, but you can see an example of the kind of filtering you can do at https://app.workbenchdata.com/workflows/5912//
The USA Spending demo makes use of regular expressions which are awesome and also exasperating. Rubular and Regex101 might make your regular expression journey more sane.
Workbench provides a case study and tutorial on cleaning data.
Christian McDonald’s 2019 NICAR workshop walks through cleaning data with regular expressions.
If you want to get fancy, David Montgomery’s 2019 NICAR workshop walks through cleaning a csv in R.
Making charts
What works
What makes a chart good? In small groups I want you to look at and discuss these three charts. Do they work?
AB 626 amends the California Retail Food Code to accommodate microenterprise home kitchens. I think there are some holes in this story about AB 626, but I know the founders of Josephine so I guess I’m a little biased. Still, they pulled out some interesting data about where the Los Angeles County Health Department hands out violations for home cooking.
» Question: Does the data bear out the caption? Countywide, 40% of residents are foreign born.
The Intercept looked at US Census tracts with serious air pollution problems, many of them concentrated in a single community.
» Question: Does the graphic add to the story? Does it help you understand the story?
CalMatters rounded up a lot of data on homelessness and renting in California.
» Question: What do you take from the Rent vs Renter Income chart?
Break

7:30 - 7:40 PM
Making good charts
Less is more

Look at what makes NYT Charts work. Design innovation is great, but there are some pretty good established formulas that we can lean on:
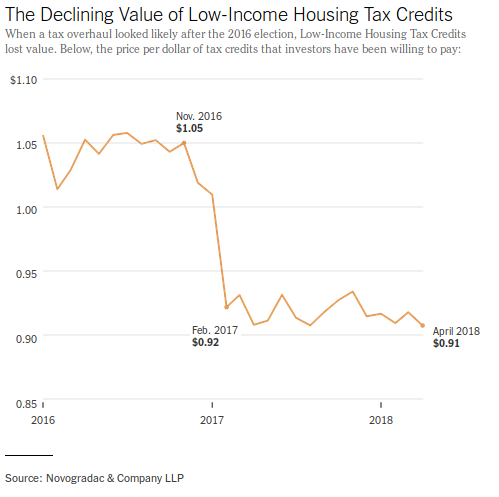
Chart from: These 95 Apartments Promised Affordable Rent in San Francisco. Then 6,580 People Applied. New York Times, May 12, 2018
This is a pretty solid example of the kind of chart that NYT does a great job with. What stands out?
- The title tells you what they see in the chart.
- The description walks you through it in clear accessible language.
- Labels direct you to key points
- Axis labels are kept to a minimum, especially when we don’t need them.
- They cite their source
Don’t make bad charts
There’s a world of really bad charts on Reddit.
Charts and illustrations should make a story more clear or draw you in. It is possible to include charts that do neither. Using this as an example might be cheating because they’re grabbing stills that are probably closer to pull quotes than anything else, but the charts are really hard to make sense of. You can use their data to revise their charts if you want to play around. Overall, there is some great reporting in CalMatter’s 2018 report on Homeless in California—what the data reveals but skim down to the charts.
» Question: Look through the CalMatters Homelessness charts. Do they hold up for you?
Three Charts from One Table
When the CDC released new data on the age at which American women give birth for the first time, they prompted a lot of different headlines. More than one proclaimed that “Millennials are having fewer children” adding “the human race” to the ever-growing list of things millennials have killed.
Are millennials really having fewer children? The answer is probably “duh, of course they are”. But looking at stories that were published when the data was released, there are a lot of examples of chart shenanigans:
One writer cribbed his charts from Business Insider, but check out the y-axis in the chart he included. And then check ou this x-axis.
» Question: What’s going on here?
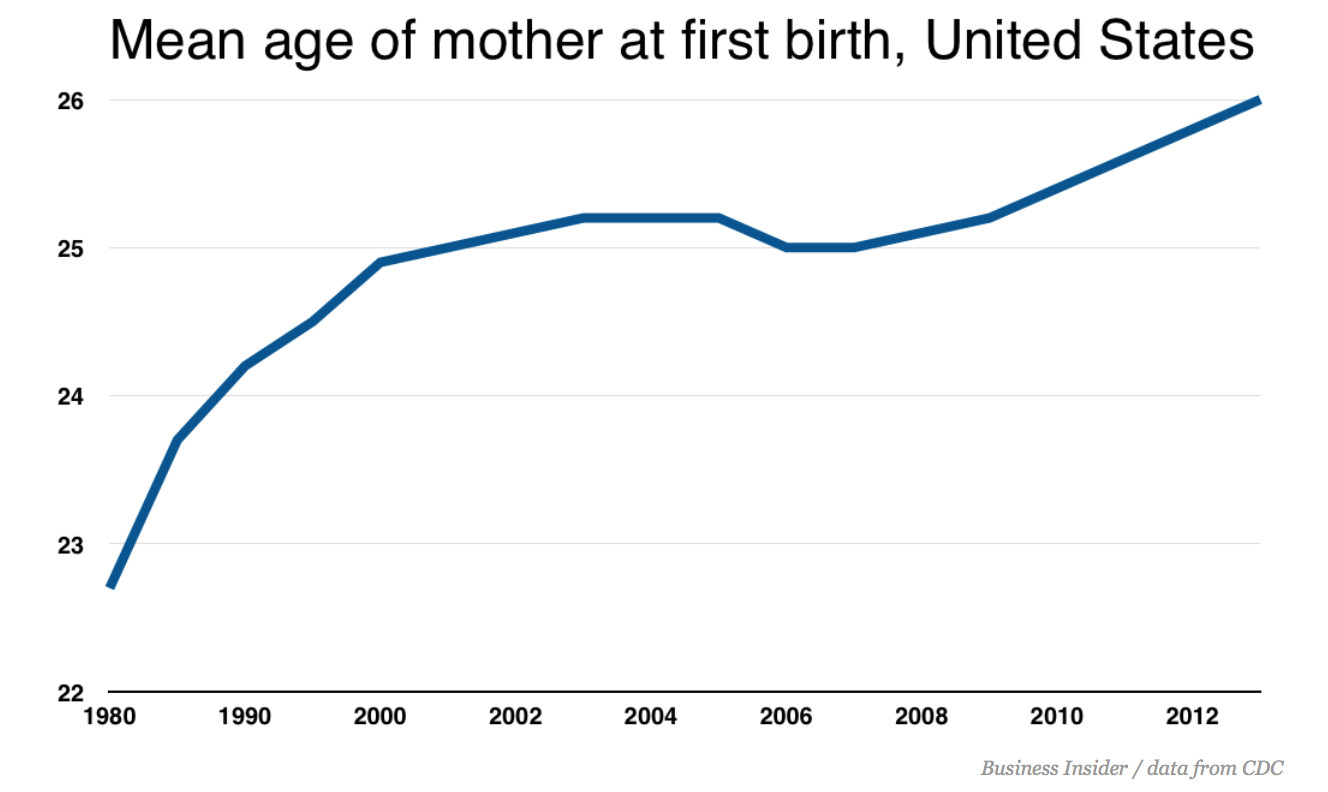
Look at the same data with a wider Y-axis spread, you see something that looks a lot more like a steady trend, as in this chart from the original CDC report suggests.
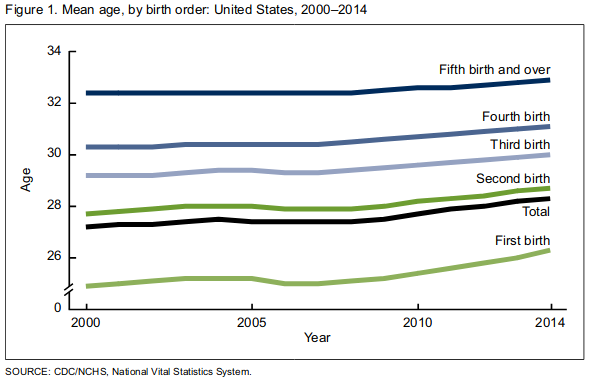
In their coverage, NPR takes a step back and looks at a longer trend.
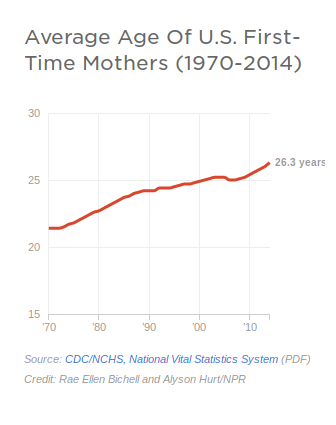
Discussion: Which y-axis is fair? What data would get at the question in the headline? We want to know the mean age at first birth, and the birth rate. And we want to know whether millennials stand out or are consistent with long-standing trends.
Chart One: Age at First Birth
I pulled the data from the CDC report cited in most of the pieces above. National Vital Statistics Reports, Vol. 64, No. 1, January 15, 2015 Table I–1. You can see what the original looked like at age_at_birth.csv. It needed some cleanup, so I processed it in Workbench: https://app.workbenchdata.com/workflows/6631/
- To chart it, we’re going to start by giving Datawrapper the URL for the raw data. https://app.workbenchdata.com/public/moduledata/live/28665.csv
- Make a new chart in Datawrapper. Use “Link External Dataset” to provide the URL.
- Power through step 2 (“Check and Describe”) but we’ll come back to it.
- Look at the raw chart.
- Back to Step 2 (“Check and Describe”) to select individual columns that we want to hide from the visualization.
- Refine, Annotate and Design it. We’ve got 3 different takes on this data to crib from. Set up a title, a description, any notes that you think are appropriate. When you’re happy with your work, publish it and share the URL, with your name, at https://etherpad.opennews.org/p/maps_and_charts
A Second Chart (ICE)
In the Spring of 2017, ICE published a report (it’s really just a press release) on their enforcement operations over the first 100 days of 2017. They included a chart in their report – what they say in the report, but not the chart, is that violent crimes including murder, rape and assault account for less than 10% of the “convicted criminals” in their data:
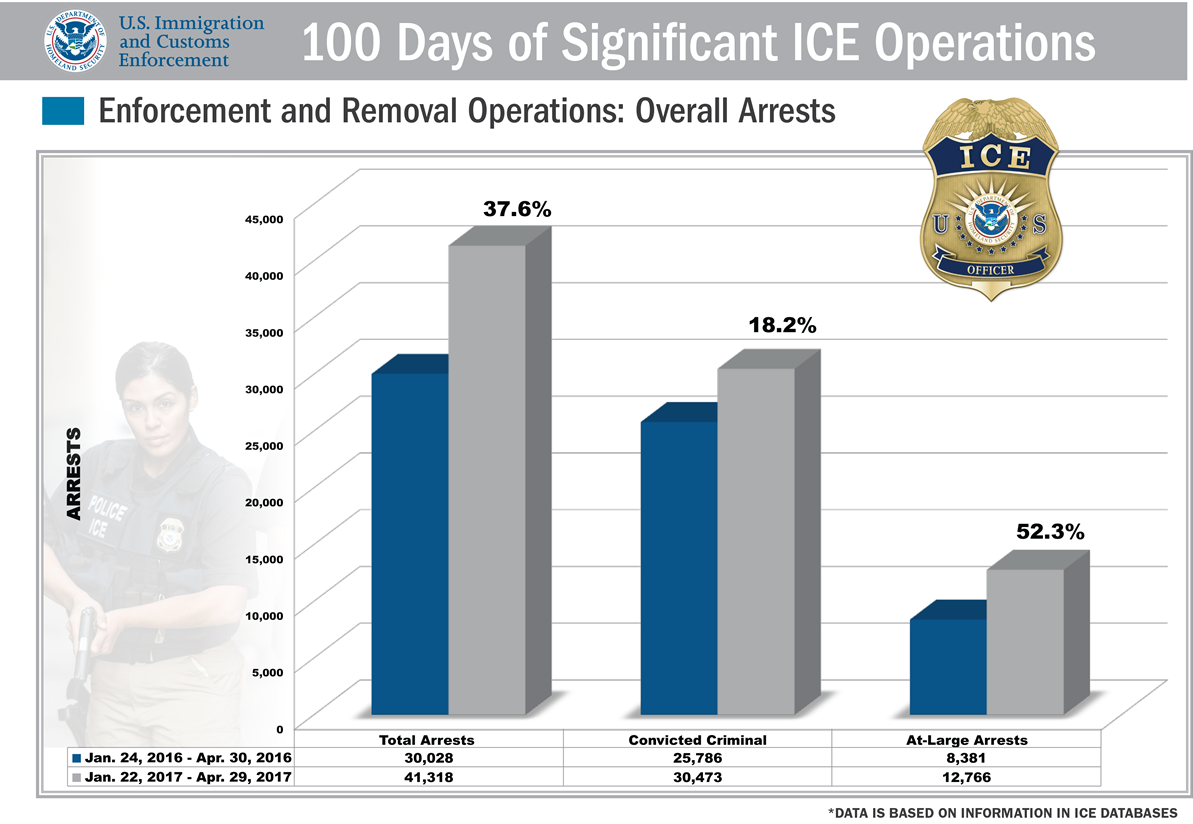
» Question: What does this chart show? What is 38%? 52%? What do those represent? What does the grey represent?
Pew covered the same numbers but added context and specificity to their chart (and ommitted the 3D renderings).
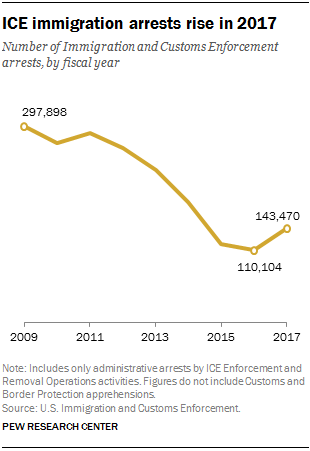
Note: What ICE is trying to show in their chart is that total arrests were up 37.6% in 2017 over the same period in 2016. Arrests of convicted criminal arrests were up 18.2% and at-large arrests (which happen in neighborhoods and at work sites) up 52.6% – their math is a little off.
I manually copied out the data from the ICE chart above. You can paste it straight into Datawrapper:
2016 2017 Percent Change
Total Arrests 30028 41318 37.6%
Convicted Criminals 25786 30473 18.2%
At-Large Arrests 8381 12786 52.6%
note: If copy and paste aren’t working for some reason, you can also grab the data as a CSV. Right click (control click on OSX) to grab the URL for the data, or download it and upload it to Datawrapper.
Spend some time in Datawrapper experimenting with how you want to display this data.
Here’s my version of those same numbers:
A Third Chart (Cocaine)
BuzzFeed News tracked Rising deaths from cocaine and methamphetamine use in part using CDC data on drug overdose deaths.
The raw data is way more than we want or need. So I processed it. https://app.workbenchdata.com/workflows/36826/
- I like to play with the “Group” step to get a sense of the data.
- Filter out just the US.
- Filter out the two categories we’re interested in: “Psychostimulants with abuse potential” and “Cocaine” – the CDC data spells out what the terms mean. Psychostimulants is more than just meth, and if you want to go back and repeat this for publication, you should make sure you really understand the data.
- Make month-by-month dates by concatenating and converting.
- Drop all the columns we don’t need
- Reshape it so we have date by drug type
Now we have something we could take over to Datawrapper.
Look up the live link for the data – if you aren’t seeing: https://app.workbenchdata.com/public/moduledata/live/185536.csv you’re doing something wrong.
Their map of drug overdose deaths is another solid exercise.
A Fourth Chart (Car Crashes)
Houston, TX averages 11 fatal car crashes every week. Reporters at the Houston Chronicle collaborated to compile and analyze data on hundreds of thousands of fatal crashes nationwide to look at why Houston’s roads are so deadly. Their series on Houston road safety started with Out of Control: Houston’s roads, drivers are country’s most deadly, Houston Chronicle, 5 September 2018.
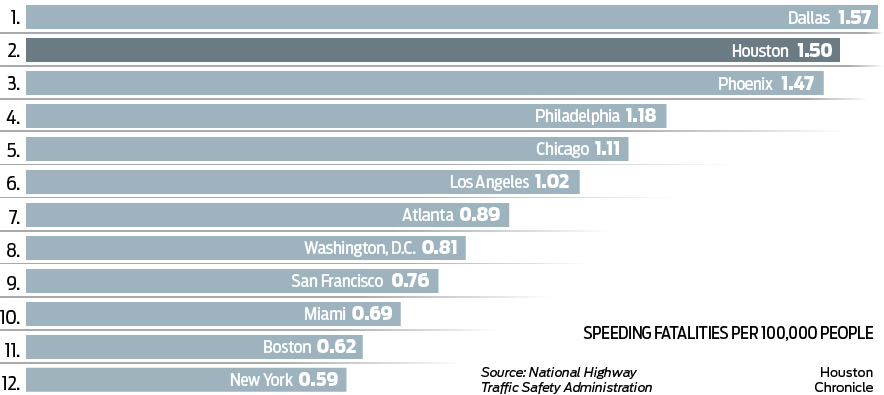
The team published the data behind their reporting, so we can replicate a lot of their analysis. I grabbed the speeding fatality data for us to work with: https://app.workbenchdata.com/workflows/12655.
Their caption is pretty good: there’s no “the chart below shows…” – instead the title points readers to what the authors think we should take away from the chart. But all the information we need for context is there. Use the speeding fatality data to replicate the chart in Datawrapper. The chart doesn’t really need a re-design, but you can re-frame it if you’d like to. Or you can just replicate their work.
Homework
Due October 24
Homework is optional but I would love it if you all would read New bill would finally tear down federal judiciary’s ridiculous paywall Ars Technica, September 17, 2018
The article includes a chart that shows just how much PACER’s revenue has grown in the 30 years since it was founded. It’s a perfectly good chart but we can definitely apply some of the basic design guidelines we looked at in class to improve on it.
Ars Technica cribbed their chart from the Free Law Project, How Much Money Does PACER Make? Free Law Project, November 14, 2016 and the Free Law Project shared the source of their data. You can pull the xls url into Workbench or just copy and paste the data. If copy and paste is acting wonky, you can also use this csv.
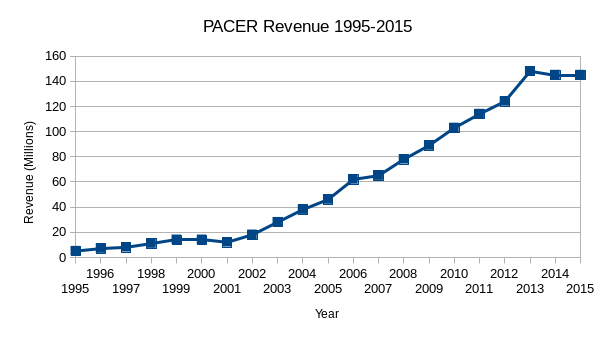
Re-make or re-design the Ars Technica chart in Datawrapper:
Year PACER Revenue (Millions)
1995 5
1996 7
1997 8
1998 11
1999 14
2000 14
2001 12
2002 18
2003 28
2004 38
2005 46
2006 62
2007 65
2008 78
2009 89
2010 103
2011 114
2012 124
2013 148
2014 145
2015 145
Post a link to your chart at: https://etherpad.opennews.org/p/maps_and_charts
For extra credit, look at the notes from the Free Law Project and see if you can find 2016 to 2018 figures. Pay attention not only to the data, but also to the framing. Give your chart a title, think about the labels you do and don’t want to include.
Note: this story is getting a tiny bit dated but it’s still a good charting exercise. PACER has reacted to this push by exp
Look for data
Identify a couple of data sources you’re interested in working with or examining. Use the guide to finding data to see if you can sort out a source. Ideally, you’ll find a data source and pull it into Workbench, but you can start by finding a few sources that are interesting to you and just letting me know where to find them.
Share the URLs at: https://etherpad.opennews.org/p/maps_and_charts
Where to find me
I’m amanda@velociraptor.info if you have any questions or want guidance or advice.
Keep learning
If you don’t have a copy of Sarah Cohen’s Numbers in the Newsroom get one. Read it through. She covers a lot of vital information about working with and writing about numbers.
If you don’t already feel comfortable with spreadsheets, you should work through the exercises in AMI’s Spreadsheet Basics. If you don’t have Safari or want additional refreshers, take a look at…
- Peter Aldhous’s Interviewing Data lesson plan from J200
- Spreadsheet Refresher from J298
- Spreadsheet Skills
If you’re ready to do more with the data and charts…
- Source publishes some fantastic guides to wrangling data and making charts, and their Things You Made series is a great place to find ideas and inspiration.
- NICAR-L
- NICAR and IRE conferences
- Stack Exchange
- Nathan Yau’s tutorials are great.
- Jeremy Singer Vine’s Intro to VisiData is a nice intro to a great tool for summary visualizations
- Conversations with Data and Data is Plural are great newsletters